天池中间件大赛百万队列存储设计总结【复赛】
维持了 20 天的复赛终于告一段落了,国际惯例先说结果,复赛结果不太理想,一度从第 10 名掉到了最后的第 36 名,主要是写入的优化卡了 5 天,一直没有进展,最终排名也是定格在了排行榜的第二页。痛定思痛,这篇文章将自己复赛中学习的知识,成功的优化,未成功的优化都罗列一下。

赛题介绍
题面描述很简单:使用 Java 或者 C++ 实现一个进程内的队列引擎,单机可支持 100 万队列以上。
1 | public abstract class QueueStore { |
编写如上接口的实现。
put 方法将一条消息写入一个队列,这个接口需要是线程安全的,评测程序会并发调用该接口进行 put,每个 queue 中的内容按发送顺序存储消息(可以理解为 Java 中的 List),同时每个消息会有一个索引,索引从 0 开始,不同 queue 中的内容,相互独立,互不影响,queueName 代表队列的名称,message 代表消息的内容,评测时内容会随机产生,大部分长度在 58 字节左右,会有少量消息在 1k 左右。
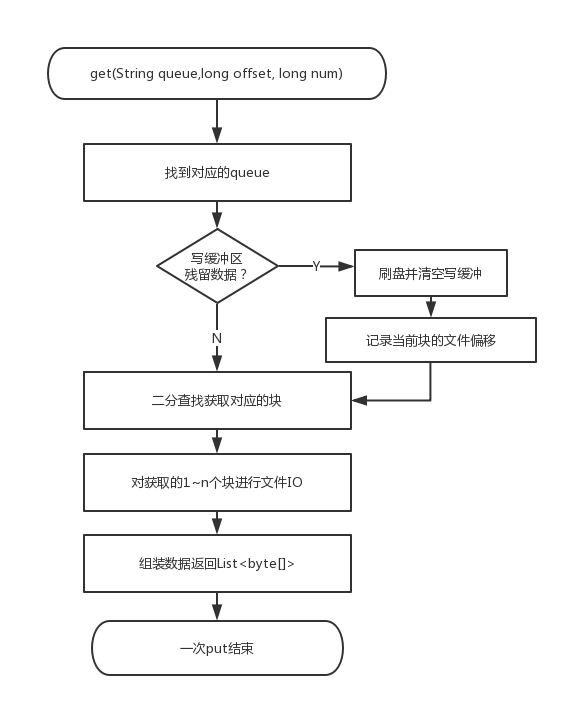
get 方法从一个队列中读出一批消息,读出的消息要按照发送顺序来,这个接口需要是线程安全的,也即评测程序会并发调用该接口进行 get,返回的 Collection 会被并发读,但不涉及写,因此只需要是线程读安全就可以了,queueName 代表队列的名字,offset 代表消息的在这个队列中的起始索引,num 代表读取的消息的条数,如果消息足够,则返回 num 条,否则只返回已有的消息即可,若消息不足,则返回一个空的集合。
** 评测程序介绍 **
- 发送阶段:消息大小在 58 字节左右,消息条数在 20 亿条左右,即发送总数据在 100G 左右,总队列数 100w
- 索引校验阶段:会对所有队列的索引进行随机校验;平均每个队列会校验 1~2 次;(随机消费)
- 顺序消费阶段:挑选 20% 的队列进行 ** 全部 ** 读取和校验; (顺序消费)
- 发送阶段最大耗时不能超过 1800s;索引校验阶段和顺序消费阶段加在一起,最大耗时也不能超过 1800s;超时会被判断为评测失败。
- 各个阶段线程数在 20~30 左右
测试环境为 4c8g 的 ECS,限定使用的最大 JVM 大小为 4GB(-Xmx 4g)。带一块 300G 左右大小的 SSD 磁盘。对于 Java 选手而言,可使用的内存可以理解为:堆外 4g 堆内 4g。
赛题剖析
首先解析题面,接口描述是非常简单的,只有一个 put 和一个 get 方法。需要注意特别注意下评测程序,发送阶段需要对 100w 队列,每一次发送的量只有 58 字节,最后总数据量是 100g;索引校验和顺序消费阶段都是调用的 get 接口,不同之处在于前者索引校验是随机消费,后者是对 20% 的队列从 0 号索引开始进行全量的顺序消费,评测程序的特性对最终存储设计的影响是至关重要的。
复赛题目的难点之一在于单机百万队列的设计,据查阅的资料显示
- Kafka 单机超过 64 个队列 / 分区,Kafka 分区数不宜过多
- RocketMQ 单机支持最高 5 万个队列
至于百万队列的使用场景,只能想到 IOT 场景有这样的需求。相较于初赛,复赛的设计更加地具有不确定性,排名靠前的选手可能会选择大相径庭的设计方案。
复赛的考察点主要有以下几个方面:磁盘块读写,读写缓冲,顺序读写与随机读写,pageCache,稀疏索引,队列存储设计等。
由于复赛成绩并不是很理想,优化 put 接口的失败是导致失利的罪魁祸首,最终成绩是 126w TPS,而第一梯队的 TPS 则是到达了 200 w+ 的 TPS。鉴于此,不太想像初赛总结那样,按照优化历程罗列,而是将自己做的方案预研,以及设计思路分享给大家,对文件 IO 不甚了解的读者也可以将此文当做一篇科普向的文章来阅读。
思路详解
确定文件读写方式
作为忠实的 Java 粉丝,自然选择使用 Java 来作为参赛语言,虽然最终的排名是被 Cpp 大佬所垄断,但着实无奈,毕业后就把 Cpp 丢到一边去了。Java 中的文件读写接口大致可以分为三类:
- 标准 IO 读写,位于 java.io 包下,相关类:FileInputStream,FileOuputStream
- NIO 读写,位于 java.nio 包下,相关类:FileChannel,ByteBuffer
- Mmap 内存映射,位于 java.nio 包下,相关类:FileChannel,MappedByteBuffer
标准 IO 读写不具备调研价值,直接 pass,所以 NIO 和 Mmap 的抉择,成了第一步调研对象。
第一阶段调研了 Mmap。搜索一圈下来发现,几乎所有的文章都一致认为:Mmap 这样的内存映射技术是最快的。很多没有接触过内存映射技术的人可能还不太清楚这是一种什么样的技术,简而言之,Mmap 能够将文件直接映射到用户态的内存地址,使得对文件的操作不再是 write/read, 而转化为直接对内存地址的操作。
1 | public void test1() throws Exception { |
如上的代码呈现了一个最简单的 Mmap 使用方式,速度也是没话说,一个字:快!我怀着将信将疑的态度去找了更多的佐证,优秀的源码总是第一参考对象,观察下 RocketMQ 的设计,可以发现 NIO 和 Mmap 都出现在了源码中,但更多的读写操作似乎更加青睐 Mmap。RocketMQ 源码 org.apache.rocketmq.store.MappedFile 中两种写方法同时存在,请教 @匠心零度 后大概得出结论:RocketMQ 主要的写是通过 Mmap 来完成。

但是在实际使用 Mmap 来作为写方案时遇到了两大难题,单纯从使用角度来看,暴露出了 Mmap 的局限性:
- Mmap 在 Java 中一次只能映射 1.5~2G 的文件内存,但实际上我们的数据文件大于 100g,这带来了第一个问题:要么需要对文件做物理拆分,切分成多文件;要么需要对文件映射做逻辑拆分,大文件分段映射。RocketMQ 中限制了单文件大小来避免这个问题。

- Mmap 之所以快,是因为借助了内存来加速,mappedByteBuffer 的 put 行为实际是对内存进行的操作,实际的刷盘行为依赖于操作系统的定时刷盘或者手动调用 mappedByteBuffer.force() 接口来刷盘,否则将会导致机器卡死(实测后的结论)。由于复赛的环境下内存十分有限,所以使用 Mmap 存在较难的控制问题。

经过这么一折腾,再加上资料的搜集,最终确定,**Mmap 在内存较为富足并且数据量小的场景下存在优势 **(大多数文章的结论认为 Mmap 适合大文件的读写,私以为是不严谨的结论)。
第二阶段调研 Nio 的 FileChannel,这也是我最终确定的读写方案。
由于每个消息只有 58 字节左右,直接通过 FileChannel 写入一定会遇到瓶颈,事实上,如果你这么做,复赛连成绩估计都跑不出来。另一个说法是 ssd 最小的写入单位是 4k,如果一次写入低于 4k,实际上耗时和 4k 一样。这里涉及到了赛题的一个重要考点:块读写。

根据阿里云的 ssd 云盘介绍,只有一次写入 16kb ~ 64kb 才能获得理想的 IOPS。文件系统块存储的特性,启发我们需要设置一个内存的写入缓冲区,单个消息写入内存缓冲区,缓冲区满,使用 FileChannel 进行刷盘。经过实践,使用 FileChannel 搭配缓冲区发挥的写入性能和内存充足情况下的 Mmap 并无区别,并且 FileChannel 对文件大小并无限制,控制也相对简单,所以最终确定使用 FileChannel 进行读写。
确定存储结构和索引结构
由于赛题的背景是消息队列,评测 2 阶段的随机检测以及 3 阶段的顺序消费一次会读取多条连续的消息,并且 3 阶段的顺序消费是从队列的 0 号索引一直消费到最后一条消息,这些因素都启发我们:应当将同一个队列的消息尽可能的存到一起。前面一节提到了写缓冲区,便和这里的设计非常契合,例如我们可以一个队列设置一个写缓冲区(比赛中 Java 拥有 4g 的堆外内存,100w 队列,一个队列使用 DirectByteBuffer 分配 4k 堆外内存 ,可以保证缓冲区不会爆内存),这样同一个缓冲区的消息一起落盘,就保证了块内消息的顺序性,即做到了”同一个队列的消息尽可能的存到一起“。按块存取消息目前看来有两个优势:
- 按条读取消息 => 按块读取消息,发挥块读的优势,减少了 IO 次数
- 全量索引 => 稀疏索引。块内数据是连续的,所以只需要记录块的物理文件偏移量 + 块内消息数即可计算出某一条消息的物理位置。这样大大降低了索引的数量,稍微计算一下可以发现,完全可以使用一个 Map 数据结构,Key 为 queueName,Value 为 List
在内存维护队列块的索引。如果按照传统的设计方案:一个 queue 一个索引文件,百万文件必然会超过默认的系统文件句柄上限。索引存储在内存中既规避了文件句柄数的问题,速度也不必多数,文件 IO 和 内存 IO 不是一个量级。
由于赛题规定消息体是非定长的,大多数消息 58 字节,少量消息 1k 字节的数据特性,所以存储消息体时使用 short+byte[] 的结构即可,short 记录消息的实际长度,byte[] 记录完整的消息体。short 比 int 少了 2 个字节,2*20 亿消息,可以减少 4g 的数据量。

稠密索引是对全量的消息进行索引,适用于无序消息,索引量大,数据可以按条存取。

稀疏索引适用于按块存储的消息,块内有序,适用于有序消息,索引量小,数据按照块进行存取。
由于消息队列顺序存储,顺序消费的特性,加上 ssd 云盘最小存取单位为 4k(远大于单条消息)的限制,所以稀疏索引非常适用于这种场景。至于数据文件,可以做成参数,根据实际测试来判断到底是多文件效果好,还是单文件,此方案支持 100g 的单文件。
内存读写缓冲区
在稀疏索引的设计中,我们提到了写入缓冲区的概念,根据计算可以发现,100w 队列如果一个队列分配一个写入缓冲区,最多只能分配 4k,这恰好是最小的 ssd 写入块大小(但根据之前 ssd 云盘给出的数据来看,一次写入 64k 才能打满 io)。
一次写入 4k,这导致物理文件中的块大小是 4k,在读取时一次同样读取出 4k。
1 | // 写缓冲区 |
不足 4k 的部分可以选择补 0,也可以跳过。评测程序保证了在 queue 级别的写入是同步的,所以对于同一个队列,我们无法担心同步问题。写入搞定之后,同样的逻辑搞定读取,由于 get 操作是并发的,2 阶段和 3 阶段会有 10~30 个线程并发消费同一个队列,所以 get 操作的读缓冲区可以设计成 ThreadLocal<ByteBuffer> ,每次使用时 clear 即可,保证了缓冲区每次读取时都是崭新的,同时减少了读缓冲区的创建,否则会导致频繁的 full gc。读取的伪代码暂时不贴,因为这样的 get 方案不是最终方案。
到这里整体的设计架构已经出来了,写入流程和读取流程的主要逻辑如下:
写入流程:

读取流程:
内存读缓存优化
方案设计经过好几次的推翻重来,才算是确定了上述的架构,这样的架构优势在于非常简单明了,实际上我的第一版设计方案的代码量是上述方案代码量的 23 倍,但实际效果却不理想。上述架构的跑分成绩大概可以达到 7080w TPS,只能算作是第三梯队的成绩,在此基础上,进行了读取缓存的优化才达到了 126w 的 TPS。在介绍读取缓存优化之前,先容我介绍下 PageCache 的概念。

Linux 内核会将它最近访问过的文件页面缓存在内存中一段时间,这个文件缓存被称为 PageCache。如上图所示。一般的 read() 操作发生在应用程序提供的缓冲区与 PageCache 之间。而预读算法则负责填充这个 PageCache。应用程序的读缓存一般都比较小,比如文件拷贝命令 cp 的读写粒度就是 4KB;内核的预读算法则会以它认为更合适的大小进行预读 I/O,比如 16-128KB。
所以一般情况下我们认为顺序读比随机读是要快的,PageCache 便是最大的功臣。
回到题目,这简直 nice 啊,因为在磁盘中同一个队列的数据是部分连续(同一个块则连续),实际上一个 4KB 块中大概可以存储 70 多个数据,而在顺序消费阶段,一次的 offset 一般为 10,有了 PageCache 的预读机制,7 次文件 IO 可以减少为 1 次!这可是不得了的优化,但是上述的架构仅仅只有 70~80w 的 TPS,这让我产生了疑惑,经过多番查找资料,最终在 @江学磊 的提醒下,才定位到了问题。

两种可能导致比赛中无法使用 pageCache 来做缓存
- 由于我使用 FIleChannel 进行读写,NIO 的读写可能走的正是 Direct IO,所以根本不会经过 PageCache 层。
- 测评环境中内存有限,在 IO 密集的情况下 PageCache 效果微乎其微。
虽然说不确定到底是何种原因导致 PageCache 无法使用,但是我的存储方案仍然满足顺序读取的特性,完全可以自己使用堆外内存自己模拟一个“PageCache”,这样在 3 阶段顺序消费时,TPS 会有非常高的提升。
一个队列一个读缓冲区用于顺序读,又要使得 get 阶段不存在并发问题,所以我选择了复用读缓冲区,并且给 get 操作加上了队列级别的锁,这算是一个小的牺牲,因为 2 阶段不会发生冲突,3 阶段冲突概率也并不大。改造后的读取缓存方案如下:

经过缓存改造之后,使用 Direct IO 也可以实现类似于 PageCache 的优化,并且会更加的可控,不至于造成频繁的缺页中断。经过这个优化,加上一些 gc 的优化,可以达到 126w TPS。整体方案算是介绍完毕。
其他优化
还有一些优化对整体流程影响不大,拎出来单独介绍。
2 阶段的随机索引检测和 3 阶段的顺序消费可以采取不同的策略,2 阶段可以直接读取所需要的数据,而不需要进行缓存(因为是随机检测,所以读缓存肯定不会命中)。
将文件数做成参数,调整参数来判断到底是多文件 TPS 高还是单文件,实际上测试后发现,差距并不是很大,单文件效果略好,由于是 ssd 云盘,又不存在磁头,所以真的不太懂原理。
gc 优化,能用数组的地方不要用 List。尽量减少小对象的出现,可以用数组管理基本数据类型,小对象对 gc 非常不友好,无论是初赛还是复赛,Java 比 Cpp 始终差距一个垃圾回收机制。必须保证全程不出现 full gc。
失败的优化与反思
本次比赛算是留下了不小的遗憾,因为写入的优化一直没有做好,读取缓存做好之后我 2 阶段和 3 阶段的总耗时相加是 400+s,算是不错的成绩,但是写入耗时在 1300+s。我上述的方案采用的是多线程同步刷盘,但也尝试过如下的写入方案:
- 异步提交写缓冲区,单线程直接刷盘
- 异步提交写缓冲区,设置二级缓冲区 64k~64M,单线程使用二级缓冲区刷盘
- 同步将写缓冲区的数据拷贝至一个 LockFreeQueue,单线程平滑消费,以打满 IOPS
- 每 16 个队列共享一个写入缓冲区,这样控制写入缓冲区可以达到 64k,在刷盘时进行排序,将同一个 queue 的数据放置在一起。
但都以失败告终,没有 get 到写入优化的要领,算是本次比赛最大的遗憾了。
还有一个失误在于,评测环境使用的云盘 ssd 和我的本地 Mac 下的 ssd 存储结构差距太大,加上 mac os 和 Linux 的一些差距,导致本地成功的优化在线上完全体现不出来,还是租个阿里云环境比较靠谱。
另一方面的反思,则是对存储和 MQ 架构设计的不熟悉,对于 Kafka 和 RocketMQ 所做的一些优化也都是现学现用,不太确定用的对不对,导致走了一些弯路,而比赛中认识的一个 96 年的小伙子王亚普,相比之下对中间件知识理解的深度和广度实在令我钦佩,实在还有很多知识需要学习。
参赛感悟
第一感受是累,第二感受是爽。相信很多选手和我一样是工作党,白天工作,只能腾出晚上的时间去搞比赛,对于 966 的我真是太不友好了,初赛时间延长了一次还算给缓了一口气,复赛一眨眼就过去了,想翻盘都没机会,实在是遗憾。爽在于这次比赛真的是汗快淋漓地实践了不少中间件相关的技术,初赛的 Netty,复赛的存储设计,都是难以忘怀的回忆,比赛中也认识了不少朋友,有学生党,有工作党,感谢你们不厌其烦的教导与发人深省的讨论,从不同的人身上是真的可以学到很多自己缺失的知识。
据消息说,阿里中间件大赛很有可能是最后一届,无论是因为什么原因,作为参赛者,我都感到深深的惋惜,希望还能有机会参加下一届的中间件大赛,也期待能看到更多的相同类型的赛事被各大互联网公司举办,和大佬们同台竞技,一边认识更多新朋友的感觉真棒。
虽然最终无缘决赛,但还是期待进入决赛的 11 位选手能带来一场精彩的答辩,也好解答我始终优化失败的写入方案。后续会考虑吸收下前几名 JAVA 的优化思路,整理成最终完善的方案。
目前方案的 git 地址,仓库已公开:https://code.aliyun.com/250577914/queuerace2018.git
** 欢迎关注我的微信公众号:「Kirito 的技术分享」,关于文章的任何疑问都会得到回复,带来更多 Java 相关的技术分享。**

天池中间件大赛百万队列存储设计总结【复赛】


