【参赛总结】第二届云原生编程挑战赛-冷热读写场景的RocketMQ存储系统设计
前言
人总是这样,年少时,怨恨自己年少,年迈时,怨恨自己年迈,就连参加一场比赛,都会纠结,工作太忙怎么办,周末休息怎么办,成年人的任性往往就在那一瞬间,我只是单纯地想经历一场酣畅的性能挑战赛。所以,云原生挑战赛,我来了,Kirito 带着他的公众号来了。
读完寥寥数百多字的赛题描述,四分之一炷香之后一个灵感出现在脑海中,本以为这个灵感是开篇,没想到却是终章。临近结束,测试出了缓存命中率更高的方案,但评测已经没有了日志,在茫茫的方案之中,我错过了最大的那一颗麦穗,但在一个月不长不短的竞赛中,我挑选到了一颗不错的麦穗,从此只有眼前路,没有身后身,最终侥幸跑出了内部赛第一的成绩。

传统存储引擎类型的比赛,主要是围绕着两种存储介质:SSD 和 DRAM,不知道这俩有没有熬过七年之痒,Intel 就已经引入了第三类存储介质:AEP(PMem 的一种实现)。AEP 的出现,让原本各司其职的 SSD 和 DRAM 关系变得若即若离起来,它既可以当做 DRAM 用,也可以当做 SSD 用。蕴含在赛题中的”冷热存储“这一关键词,为后续风起云涌的赛程埋下了伏笔,同时给了 AEP 一个名分。
AEP 这种存储介质不是第一次出现在我眼前,在 ADB 比赛中就遇到过它,此次比赛开始时,脑子里面对它仅存的印象便是”快”。这个快是以 SSD 为参照物,无论是读还是写,都高出传统 SSD 1~n 个数量级。但更多的认知,只能用 SSD 来类比,AEP 特性的理解和使用方法,无疑是这次的决胜点之一。
曾经的我喜欢问,现在的我喜欢试。一副键盘,一个深夜,我窥探到了 AEP 的奥秘,多线程读写必不可少,读取速度和写入速度近似 DRAM,但细究之下写比读慢,从整体吞吐来看,DRAM 的读写性能略优于 AEP,但 DRAM 和 AEP 的读写都比 SSD 快得多的多。我的麦穗也有了初步的模样:第一优先级是降低 SSD 命中率,在此基础上,提高 DRAM 命中率,AEP 起到平衡的效果,初期不用特别顾忌 AEP 和 DRAM 的命中比例。
参赛历程
万事开头难,中间难,后段也难。
和参加比赛的大多数人一样,我成功卡在了第一步:出分。AEP 先别用了,缓存方案也暂且搁置,不愧是 RocketMQ 团队出的题目,队列众多,那就先用 RocketMQ 的经典方案,“一阶段多线程绑定分区文件,顺序追加写,索引好办,内存和文件各存一份;二阶段随机读”,说干就干,两个小时后,果然得到了“正确性检测失败”的提示。把时间轴拉到去年,相比之下今年的参赛队伍并没有降低很多,但出分的队伍明显下降,大多数人是卡在了正确性检测这一关。咨询出题人,得知这一次的正确性检测是实实在在的”掉电“,PageCache 是指望不上了,只能派 FileChannel#force() 出场,成功获得了第一份成绩:1200s,一份几乎快超时的成绩。
使用 force 解决掉电数据不丢失可以参考我赛程初段写的文章:https://www.cnkirito.moe/filechannel_force/
优化成功的喜悦片刻消散,初次出分的悸动至死不渝。那种感觉就像一觉醒来,发现今天是周六,可以睡到中午,甚至后面还有一个周日一样放肆。有了 baseline,下面便可以开始着手优化了,刚起头儿,有的是功夫,有的是希望。
掉电的限制,使得 SSD 的写入方案十分受限,每一条数据都要 force,使得 pageCache 近似无效,pageCache 从来没有受过这样的委屈,我走还不行吗?
随着赛程持续推进,也就推进了一天吧,我开始着手优化合并写入方案。传统方案中,聚合写入往往使用 DRAM 作为写入缓冲,聚合同一线程内前后几条消息,以减少写入放大问题,也有诸如 MongoDB 之流,会选择合并同一批次多个线程之间的数据,按照题意,多个线程合并写入,一起 force 已然是题目的唯一解。团结就是力量,经过测试,n 个线程聚合在一起 force,一起返回,可以显著降低 force 的总次数,缓解写入放大问题,有效地提升了分数。n 多少合适呢?理论分析,n 过大,实际 IO 线程就会变少;n 过小,force 次数多,解决调参问题,最合适的是机器学习,其次是 benchmark,经过多轮 benchmark,4 组 x 10 线程最为合适,4 个 IO 线程正好 = CPU core,这非常的合理。
合并写入后,效果显著,成绩来到了 700~800s。如果没有 AEP,这个比赛也就到头了,AEP 的加入,像草一样,一切都卷了起来。
赛程中段,有朋友在微信交流群中问我,AEP 你有用起来吗?每个人都会经历这个阶段:看见一座山,就想知道山后面是什么。我很想告诉他,可能翻过去山后面,你会发觉没有什么特别。回头看,会觉得这一边更好。但我知道他不会听,以他的性格,自己不试过,又怎么会甘心?我的 trick 无足轻重,他最终还是使用了 AEP,感受到了蒸汽火车到高铁那般速度的提升。总数据 125G,AEP 容量 60G,即使固定存储最后的 60G 数据,也可以确保热读部分的数据全部命中 AEP,SSD 会因为你的刻意保持距离而感到失落,你的分数不会。
即便是这样不经任何设计的 AEP 缓存方案,得益于 AEP 的读写速度和较大的容量加持,也可以获得 600s+ 的分数。
分数这个东西,总是比昨天高一点,比明天少一点,但要想维持这样的分数增长,需要持续付出极大的努力。600s 显然不足以支撑进入决赛,AEP 缓存固定的数据也显得有点呆,就像你意外获得了一块金刚石,不经雕琢,则无法成为耀眼夺目的钻石。必须优化 AEP 的使用方案!因为有热数据的存在,写入的一部分数据会在较短的一段时间内被消费,缓存方案也需要联动起来,写入-> 消费 -> 写入 -> 消费,大脑中飞速地模拟、推测评测程序的流程,操作系统、计算机网络的概念被一遍遍检索,最终锁定在了一个耳熟能详的概念:TCP 滑动窗口。AEP 保存最热的 60G 数据,使得热读全部命中,根据测试,发现冷读也会很快变成热读,在思路和方案连接的那一刻,代码流程也直接显现了出来,三又二分之一小时后,我提交了这份 AEP 滑动窗口的方案,没有什么比一次 Acccept 更爽的事了,一边赞叹自己的编码能力,一边自负地停止了优化,成绩停留在了 504s。
十月八号零点八分,钟楼敲响后的八分钟,我手握着一杯水,打开了排行榜,看到不少 500+ 的分数,懊恼、恐慌、焦虑一下子涌上了心头,水也越饮越寒。我本有七天时间,优化我的方案,但我没有;我在等一个奇迹,期待大家忘掉这场比赛,放弃优化,让排行榜锁定在十月一号那一天,但它没有。我将这份烦恼倾诉给妻子,换来了她的安慰,在她心目中,我永远是最棒的。我内心忐忑地依附道,那当然…在之后的晚上,世上少了一个 WOT 的玩家,多了一个埋头在 IDEA 中追求极致性能的码农。
在很长的一段时间里,我一直在追求降低 SSD 的命中率,每降低一点,我的分数总能够提升几秒。不知道从哪一天起,我看到排行榜中出现了一些 450s 的成绩,起初这并没有引起的我的警觉,因为 hack 可以很容易达到 300s,我一开始预估的极限成绩,不过也就是 470s,对,这一定是 hack,心里一遍遍地默念着。但,万一不是呢?
太想伸手摘取星星的人,常常忘记脚下的鲜花。我开始翻阅赛题描述,以寻找是否有遗漏的信息;一遍遍 review 自己的代码,调整代码结构,优化代码细节;检索自己过往的博文,以寻找可能擦肩而过的优化点。往后的几个晚上,我做的是同一个梦,梦里面重复播放着自己曾经的优化经验:4kb 对齐、文件预分配、缓存行填充…忽然间想起,自己总结的优化经验还没有完全尝试过。这次比赛是从第一次写入开始计时的,选手们可以在构造函数中恣意地预先分配一些数据,例如对象提前 new 好,内存提前 allocate,减少 runtime 时期的耗时,而这其中最有用的优化,当属 SSD 文件的预分配和 4kb 填充了。在 append 之前,事先把文件用 0 填充,得到总长度略大于 125G 的空白文件,在写入时,不足 4kb 的部分使用 4kb 填充,即使多写了一部分数据,速度还是能够提升,换算成实际的写入速度,可以达到 310M/s,而在此之前,force 的存在使得写入瓶颈始终卡在 275M/s。宁可一思进,莫在一思留,方案调通后,成绩锁定在了 440s。
内部赛结束前的两周,我又萌生了一个大胆的想法,考虑到 getRange 命中 SSD 时,系统采用的是抽样检测,那是不是意味着,用 mmap 读取就变成了一种懒加载呢?这个思路虽然在实际生产中不太通用,但在赛场上,那可以一把利器,这把利器斩下了 412s 的分数,也割伤了自己,评委不让用!我的天,我浪费了宝贵的两周,浪费在了一个无法通过的方案上。天知道评测是在抽样检测,我只是认为 mmap 读会更快呀 :)
不知道从什么时候开始,在什么东西上面都有个日期,秋刀鱼会过期,肉罐头会过期,比赛也在 10.26 号这天迎来了结束。未竟的优化,设想的思路,没能完成方案改造的遗憾都在这一刻失去了意义。我已经很久没有打过比赛了,也很久没有这样为一个方案绞尽脑汁了,这场比赛就这样任性地画上了一个句号。
最终方案
SSD 写入方案
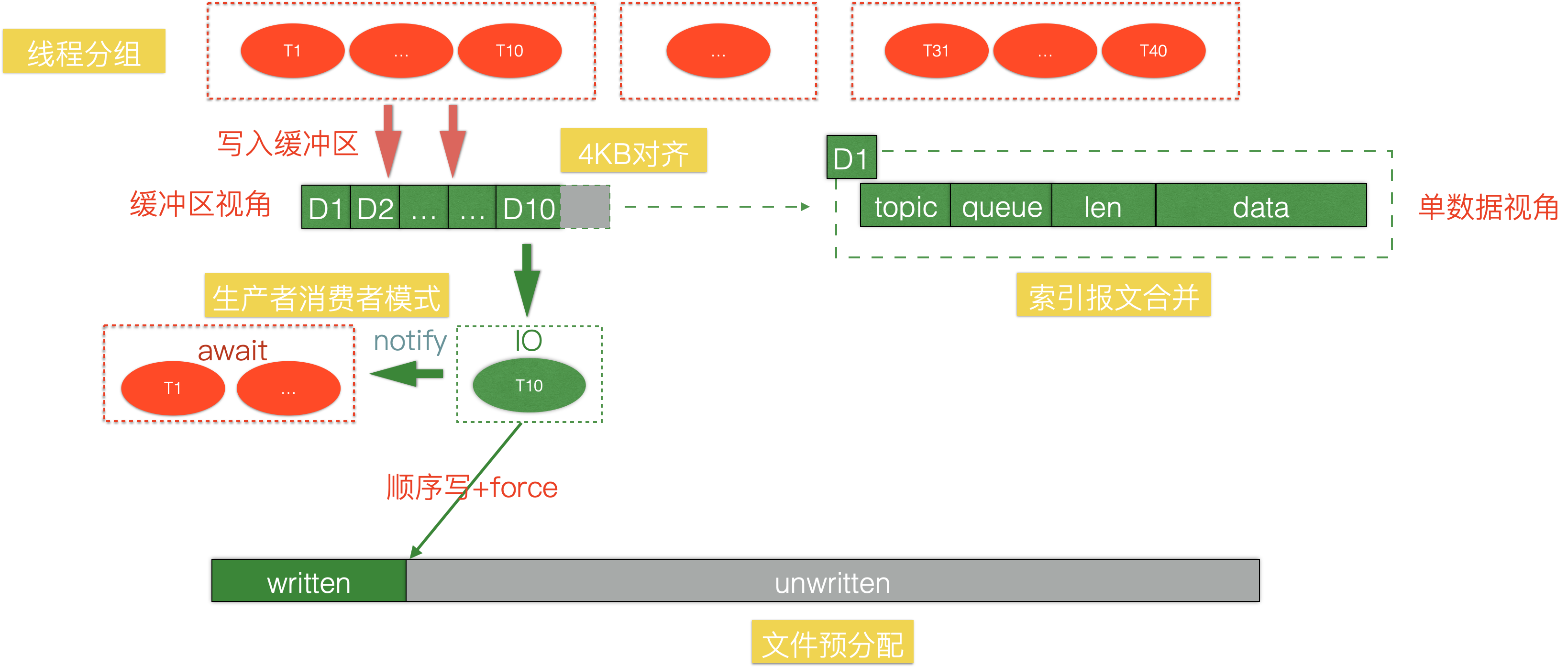
缓存架构是制胜点,SSD 的写入方案则是基本面,相信绝大多数前排的选手,都采用了上述的架构。性能评测阶段固定有 40 个线程,我将线程分为了 4 组,每组 10 个线程,进行 IO 合并。为什么是 4组在参赛历程中也介绍过,尊重 benchmark 的结果。1~9 号线程写入缓冲区完毕之后就 await 进入阻塞态,留下 10 号线程进行 IO,刷盘之后,notify 其他线程返回结果,如此往复,是一个非常经典的生产者消费者模式。
由于这次比赛,recover 阶段是不计入得分的,为了降低 force 的开销,我选择将索引的持久化和数据存在一起,这样避免了单独维护索引文件。在我的方案中,索引需要维护 topic,queue,length 三个信息,只需要定长的 5 个字节,和 100b~17Kb 的数据相比,微不足道,合并之后收益是很明显的。
选择使用 JUC 提供的 Lock + Condition 实现 wait/notify,一则是自己比较习惯这么控制并发,二则是复用其中一个 append 线程做刷盘的 IO 线程,相比其他并发方案的线程切换,要少一点。事实上,这次比赛中,CPU 是非常富余的,不会成为瓶颈,该模式的优势并没有完全发挥出来。
4kb 对齐是 SSD 经典的优化技巧,尽管并不是每一次性能挑战赛它都能排上用场,但请务必不要忘记尝试它。它对于人们的启发是使用 4kb 整数倍的写入缓冲聚合数据,整体刷盘,从而避免读写放大问题。此次比赛稍显特殊,由于赛题数据的随机分布特性,10 个线程聚合后的数据,往往不是 4KB 的整数倍,但这不妨碍我们做填充,看似多写入了一部分无意义的数据,但实际上会使得写入速度得到提升,尤其是在 force 情况下。
我曾和 @chender 交流过 4KB 填充这个话题,尝试分析出背后的原因,这里的结论不一定百分之百正确。4KB 是 SSD 的最小读写单元,这涉及硬件的操作,如果不填充,考虑以下执行流程,写入 9KB,force,写入 9 Kb,force,如果不做填充,相当于 force 了 9+3+3+9+3=27 kb,中间交叉的 3 kb,在 force 时会被重复计算,而填充过后,一定是 force 了 9+3+9+3=24 kb,整体 force 量降低。还有一个可能的依据是,没有填充的情况下,其实一定程度破坏了顺序写,写入实际写入了 12kb,但第二次写入并没有从 12kb 开始写入,而是从 9kb 写入。总之在 benchmark 下,4kb 对齐确实带来了 15s+ 的收益。
写入阶段还有一个致胜的优化,文件预分配。在 C 里面,有 fallocate,而 Java 并没有对应的 JNI 调用,不过可以取巧,利用 append 开始计分这个评测特性,在 SSD 上先使用字节 0 填充整个文件。在预分配过后,使用 force 也可以获得跟不使用 force 一样的写入速度,几乎打满了 320M/s 的 IO 速度。这个优化点,我在之前的博客中也分享过,不知道有没有其他选手看到并利用了起来,如果漏掉了这个优化,真的有点可惜,因为它足足可以让方案快 50s 左右。
缓存架构
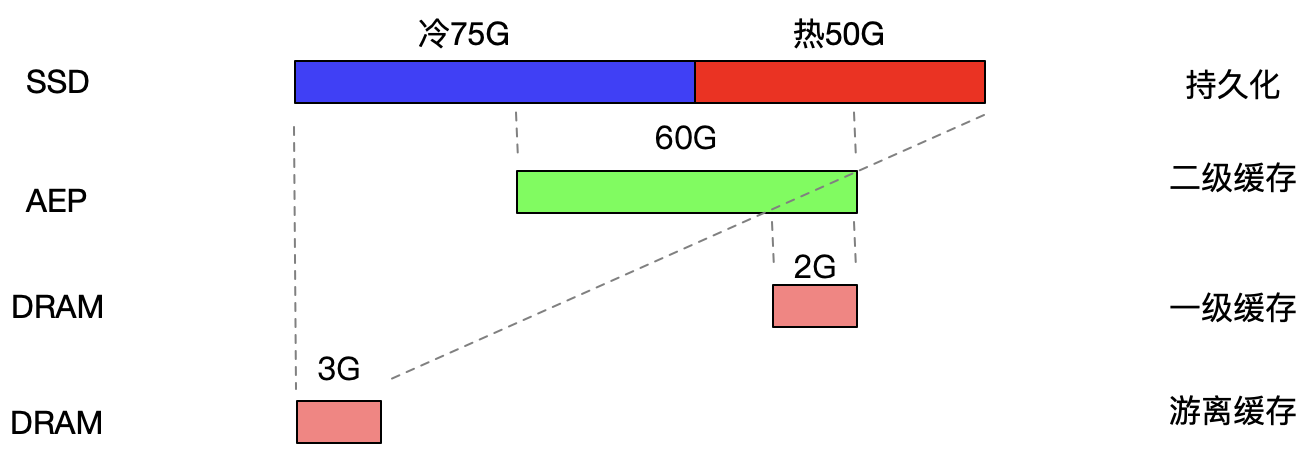
上图是全局缓存架构,整体方案的思路是多级缓存,采用滑动窗口的思想,AEP 永远缓存最新的 60G 数据,以确保热数据一定不会命中 SSD。同时,堆外的 2G DRAM 与 AEP 息息相关,这部分 DRAM 有两个作用,其一是作为 AEP 的写入缓冲,规避 AEP 写入放大的问题,其二是作为热数据的 DRAM 缓存,最热的一部分数据,可以保证直接命中 DRAM,规避 AEP 的访问。另外富余的 3G 的堆内内存,可以用于缓存由于滑动而导致被覆盖的数据,这部分 DRAM 同时配备引用计数,从而达到复用的效果。
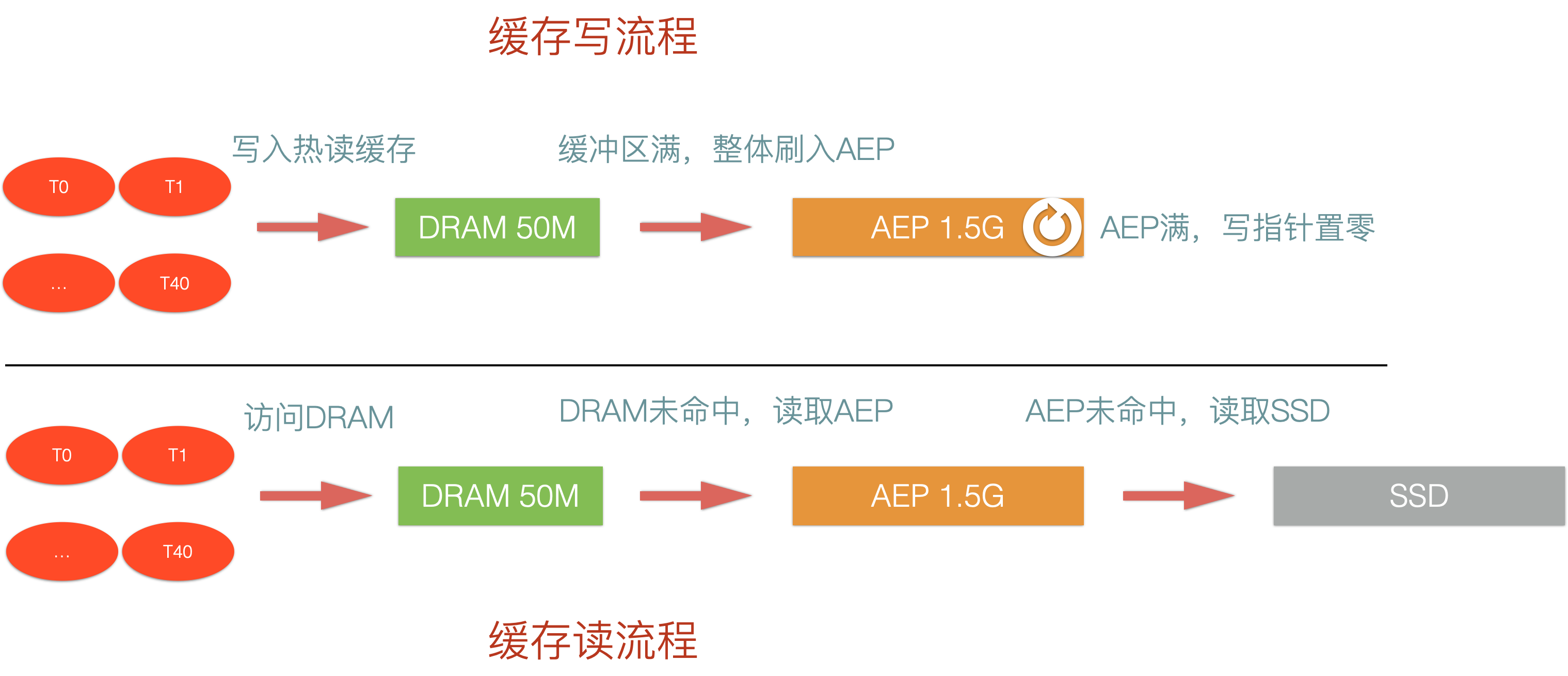
在具体实现中,我将 60G 平均分配给 40 个线程,每个线程持有 1.5G 的 AEP 可用缓存,50M 的 DRAM 缓存。可以发现,在我的方案中,SSD 写入方案和 AEP 是不同的,SSD 由于 force 的限制,采用了线程合并写入,而 AEP 本身就是可以丢失的缓存,所以不需要进行合并,每个线程维护自身的 AEP 和 DRAM 缓存即可。
每个线程除了配备 1.5G 的AEP,还分配了 50M 的 DRAM。这部分 DRAM 永远被优先写入,同样的,也会优先被读取,前提是命中了的话。50M 显然不是一个特别大的空间,所以在其充满时,将 50M 数据整体刷入 AEP 中,使用 ByteBuffer 作为 DRAM 的 manager,还可以利用其逻辑 clear 的操作,使得 DRAM 和 AEP 一样变成了一个 RingBuffer。这部分设计算是我方案中比较巧妙的一点。
当然,你永远可以相信 SSD,它是最后一道兜底逻辑,无论缓存设计的多么糟糕,保证最后能够命中 SSD 才能出分,所有人都清楚这一点。
AEP 滑动窗口的实现其实并不复杂,详见文末的代码,我就不过多介绍了。
程序优化
预分配文件
1 | public static void preAllocateFile(FileChannel fileChannel, long threadGroupPerhapsFileSize) { |
简单实用的一个优化技巧,属于发现就可以很快实现的一个优化,但可能不容易发现。
4KB 对齐
1 | private void force() { |
同上
Unsafe
其实感觉用了 Unsafe 也没有多少提升,因为后期抖动太大了,但最优成绩的确是用 Unsafe 跑出来的,还是罗列出来,万一下次有用呢?详见代码实现 io.openmessaging.NativeMemoryByteBuffer。
推荐阅读:《聊聊Unsafe的一些使用技巧》
ArrayMap
可以使用数组重写一遍 Map,反正此次比赛调用到的 Map 的 API 也不多,换成数组实现之后,可以降低 HashMap 的 overheap,再优秀的实现,在数组面前也会变得黯淡无光,仅限于比赛。
详见代码实现 io.openmessaging.ArrayMap。
预初始化
充分利用 append 之前的耗时不计入总分这一特性。除了将文件提前分配出来之外,Runtime 需要 new 的对象、DRAM 空间等,都提前在构造函数中完成,蚊子腿也是肉,分数总是这么一点点抠出来的。
并发 getRange
读取阶段 fetchNum 最大为 100,串行访问的话,如果是命中缓存还好,要是 100 次 SSD 的 IO 都是串行,那可就太糟糕了。经过测试,仅当命中 SSD 时并发访问,和不区分内存、AEP、SSD 命中,均并发访问,效果差不多,但无论如何,并发 getRange 总是比串行好的。
ThreadLocal 复用
性能挑战赛中务必要 check 的一个环节,便是在运行时有没有动态 new 对象,有没有动态 allocate 内存,出现这些可是大忌,建议全部用 ThreadLocal 缓存。这次的赛题中有很多关键性的数字,100 个 Topic、40 个线程,稍加不留意,可能把线程级别的一些操作,错当成 Topic 级别来设计,例如分配的写入缓冲也好,getRange 阶段复用的读取缓冲也好,都应该设计成线程级别的数据。ThreadLocal 第一是方便管理线程级别的资源,第二是因为线程相对于 Topic 是要少的,需要搞清楚,哪些资源是线程级别的,哪些是 Topic 级别的,避免资源浪费。
合并写入
详见源码io.openmessaging.ThreadGroupManager#append
AEP 滑动窗口
详见源码io.openmessaging.AepManager
总结与反思
一言以蔽之,滑动窗口缓存是我整个方案的核心,虽然这个方案经过细节的优化,让我取得了内部赛第一的成绩,但开篇我也提到过,它并不是缓存命中率最高的方案,在这个方案中,第一个明显的问题便是,堆外 DRAM 和 AEP 可能缓存了同一批数据,实际上,DRAM 和 AEP 缓存不重叠的方案肯定会有更高的缓存命中率;第二个问题,也是问题一连带的问题,在该方案中,堆内的 DRAM 无法被很高效地利用起来,所以我在本文中,只是稍带提了一下堆内的设计,没有详细介绍引用技术的逻辑。
我在赛程后半段,也尝试设计过 DRAM 和 AEP 不重叠并且动态分配回收的方案,缓存利用率的确会更高,但这意味着我要放弃滑动窗口方案中所有的细节调优!业余时间搞比赛,实在是精力时间有限,最终选择了放弃。
这像极了项目开发的技术债,如果你选择忍受,你可以得到一个尚可使用的系统,但你知道,重构之后,它可以更好;当然你也可以选择重构,死着皮,连着肉。
重赏之下,必有卷夫。内部赛还好,外部赛实在是卷,每次这种性能挑战赛,打到最后都是拼了命的抠细节,你被别人卷到了,就很累,你想到了优化点,卷到了别人,就很爽,这也太真实了。
最后说说收获,这次比赛,让我对 AEP 这个新概念有了比较深的理解,对存储设计、文件 IO 也有了更深的体会。这类比赛偶尔打打还是挺有意思的,一方面写项目代码容易疲乏,二是写出这么一个小的工程,还是挺有成就感的一件事。如果有下一场,也欢迎读者们一起来卷。
源码
https://github.com/lexburner/aliyun-cloudnative-race-mq-2021.git
【参赛总结】第二届云原生编程挑战赛-冷热读写场景的RocketMQ存储系统设计


